Towards a better prediction of civil wars - Correcting an imbalanced dataset
This website displays the results of team GYC's project for the ADA course during the autumn semester of 2020

Introduction
Civil wars are devastating and to prevent or at least contain them, accurately predicting their onset is crucial. In this paper, the authors focus on analysing the civil war onset predictive performance by comparing the performance of Random Forests (RFs), machine learning method applied in political science to increase predictive accuracy, with three logistic regression approaches, namely standard logistic regression, Firth’s penalized logistic regression and L1-regularized logistic regression models. The models were trained using cross-validation, which allows examining the predictive power of statistical models without collecting new data.
The evaluation of RFs and logistic regression of correctly predicting true instances of civil war onset through Receiver Operating Characteristic (ROC) curves showed that RFs performed excellently, while logistic regressors ranged from average to good. Moreover, RFs outperformed the other methods, in terms of both higher average F1-score and lower standard deviation. All in all, it was concluded from the results that statistical learning methods such as RFs have superior predictive accuracy in class imbalanced Civil War Dataset and can understand its causes. Accordingly RFs can be applied in the political science field, as they are easy to interpret, robust to outliers and allow correcting for class-imbalanced data.
In this extension, we explore methods to overcome the unbalance in the data classes. First, we apply data correction methods such as boosting and sampling on the same dataset used in the paper expecting to improve the logistic regression model’s accuracy. Then we explore other classifiers aiming to get the best possible predictive results on the corrected data. Cross validation is applied here as it produces unbiased and accurate error rates. In assessing the predictive performance, we use the following metrics; F1 score, Receiver Operating Characteristic Curve and AUC score.
Results
First, we started replicating what the authors did in the paper Comparing Random Forest with Logistic Regression for Predicting Class-Imbalanced Civil War Onset Data. In addition, we used oversampling to test and as we will see in the table at the end, it gave better performances in terms of F1 score.

In a second time, we decided to change an aspect of their paper, which was that the models they compared did not have the same features. It was thus not accurate to compare them. We decided to use all the features we could to train our models.

What came out of this first change is that, without any surprise, the regression stays less performant than the random forest. Though it performed better when using the data correction methods we used, that is to say oversampling and adaboost. We did not use undersampling because of the lack of sample in the minority class.
Oversampling generates new data points for the minority to have the same amount than the majority class.We decided to use the Synthetic minority oversampling technique (SMOTE) that generates new samples between existing data points based on local density and their border with the other class. It is an informed oversampling method that is less prone to overfitting than a random oversampling method.
Boostings methods are algorithms that convert weak learners into strong learners in order to improve the prediction power. It will first identify the weak learners and combine them into one strong learner.
We then tried several models in order to find one that could surpass the final model of the paper.


To draw a first conclusion, the only model that performed better was gradient boosting, as we can see on the ROC curves.
Summary of the best models’ performances
To look from another point of view, we got the F1 score of the methods we tested previously. The F1 score is calculated by doing : (Precision*Recall)/(Precision+Recall). In the table, the F1 score will be approximated to zero if the value is really small.
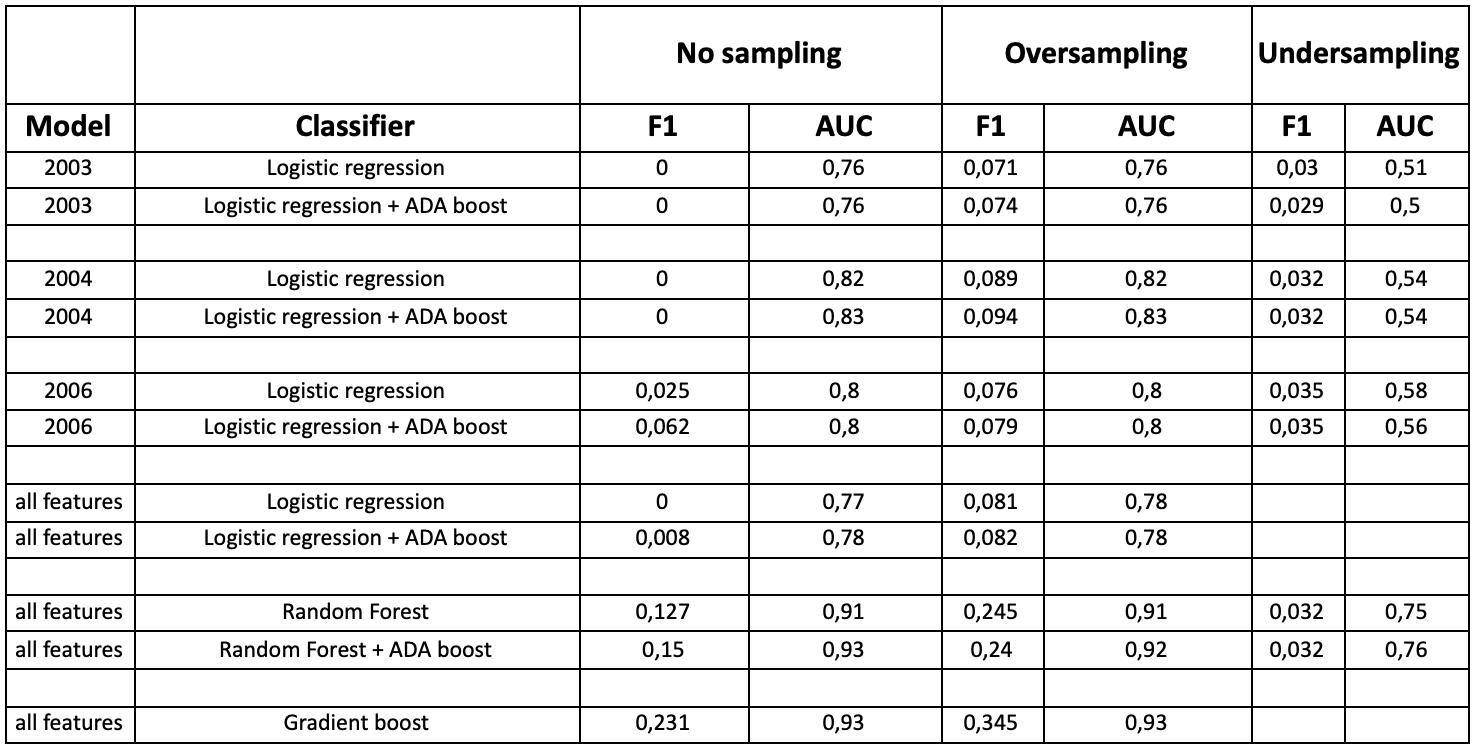
Looking only at the AUC Score, we would think that the sampling methods didn’t improve the predictions at all. But if we compare it with the F1 score, we see that there is a significant improvement when we apply a sampling method, especially for oversampling.
Conclusion
We can conclude that the paper’s methods were fairly accurate in terms of predictions. However we showed they compared their method with models that could still be improved, notably with data correction methods such as sampling and boosting. As we saw in the last table, the metrics used to compare these methods is also an important factor that we need to take in account and it is wise to use different metrics before drawing any conclusion. Moreover the use of the same features in each of the model, regressions and random forest, was necessary to draw fair comparisons.
Eventually, we found a model that overperformed the random forest model they used; indeed the results that came out of the gradient boosting model were just above that of the random forest of the authors.